



多任务
介绍
多任务最大的好处就是充分利用CPU资源,提高程序的执行效率
概念
多任务是指在同一时间内执行多个任务
执行方式
并发
在一段时间内交替去执行任务

并行

进程
python程序中,想要实现多任务可以使用进程完成,进程是实现多任务的一种方式
概念

注意

作用
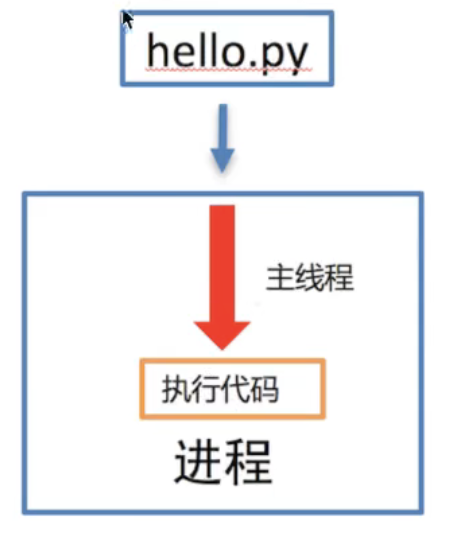
单进程效果图
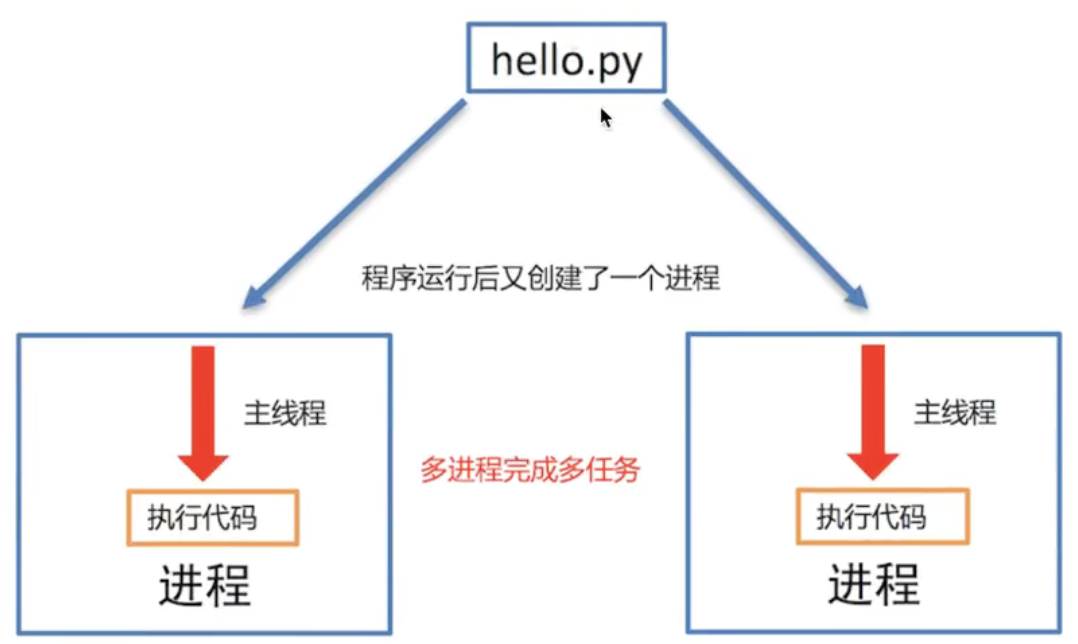
多进程效果图
小结
- 进程是操作系统进行资源分配的基本单位
- 进程是python程序中实现多任务的一种方式
多进程的使用
导入进程包
import multiprocessing
Process进程类的说明

示例一
主进程执行一个任务,创建一个新进程执行一个任务
代码
# 导入进程包
import multiprocessing
import time
# 吃饭任务
def eat():
for i in range(3):
print("吃饭中...")
time.sleep(0.2)
# 喝水任务
def drink():
for i in range(3):
print("喝水中...")
time.sleep(0.2)
# 创建子线程执行喝水任务
# target:进程执行的目标任务
if __name__ == '__main__':
drink_process = multiprocessing.Process(target=drink)
# 启动进程执行对应的任务
drink_process.start()
# 主进程执行吃饭任务
if __name__ == '__main__':
eat()
输出
吃饭中...
喝水中...
吃饭中...
喝水中...
吃饭中...
喝水中...
示例二
主进程不执行任务,创建两个新进程执行两个任务
代码
# 导入进程包
import multiprocessing
import time
# 吃饭任务
def eat():
for i in range(3):
print("吃饭中...")
time.sleep(0.2)
# 喝水任务
def drink():
for i in range(3):
print("喝水中...")
time.sleep(0.2)
# 创建子线程执行喝水任务
# target:进程执行的目标任务
if __name__ == '__main__':
drink_process = multiprocessing.Process(target=drink)
eat_process = multiprocessing.Process(target=eat)
# 启动进程执行对应的任务
drink_process.start()
eat_process.start()
输出
吃饭中...
喝水中...
吃饭中...
喝水中...
吃饭中...
喝水中...
注意
进程执行是无序的,具体哪个进程先执行是由操作系统调度决定的
获取进程编号
代码示例
# 导入进程包
import multiprocessing
import time
import os
# 吃饭任务
def eat():
# 获取当前进程(子进程)的编号
eat_process_id = os.getpid()
# 获取当前进程对象-查看当前代码是由哪个进程执行的-multiprocessing.current_process
print("吃饭进程的ID是:", eat_process_id, multiprocessing.current_process())
# 获取当前进程的父进程编号
eat_parent_process_id = os.getppid()
print("吃饭进程的父进程编号是:", eat_parent_process_id)
for i in range(3):
print("吃饭中...")
time.sleep(0.2)
# 扩展:根据进程编号强制杀死指定进程
os.kill(eat_process_id, 9)
# 喝水任务
def drink():
# 获取当前进程(子进程)的编号
drink_process_id = os.getpid()
# 获取当前进程对象-查看当前代码是由哪个进程执行的-multiprocessing.current_process
print("喝水进程的ID是:", drink_process_id, multiprocessing.current_process())
# 获取当前进程的父进程编号
drink_parent_process_id = os.getppid()
print("喝水进程的父进程编号是:", drink_parent_process_id)
for i in range(3):
print("喝水中...")
time.sleep(0.2)
if __name__ == '__main__':
# 获取当前进程(主进程)的编号
main_process_id = os.getpid()
# 获取当前进程对象-查看当前代码是由哪个进程执行的-multiprocessing.current_process
print("主进程的ID是:", main_process_id, multiprocessing.current_process())
# 创建子线程执行喝水任务
# 参数1:group:进程组,目前只能使用None,一般不需要设置
# 参数2:target:进程执行的目标任务
# 参数3:name:进程名,如果不设置默认是Process-1,Process-2...
drink_process = multiprocessing.Process(target=drink, name="drink_process")
print("drink_process:", drink_process)
eat_process = multiprocessing.Process(target=eat, name="eat_process")
print("eat_process:", eat_process)
# 启动进程执行对应的任务
drink_process.start()
eat_process.start()
输出
主进程的ID是: 67270 <_MainProcess name='MainProcess' parent=None started>
drink_process:
eat_process:
喝水进程的ID是: 67272
喝水进程的父进程编号是: 67270
喝水中...
吃饭进程的ID是: 67273
吃饭进程的父进程编号是: 67270
吃饭中...
喝水中...
喝水中...
进程执行带有参数的任务
介绍
Process类执行任务并给任务传参数有两种方式:
- args表示以元祖方式给执行任务传参
- kwargs表示以字典方式给执行任务传参
args参数的使用
# 以元祖方式传参,元祖里面的元素顺序要和函数的参数顺序保持一致
# sub_process = multiprocessing.Process(target=info_print, args=("laifu", 1.1))
# sub_process.start()
kwargs参数的使用
# 以字典方式传参,字典里的key要和函数里面的参数名保持一致,没有顺序要求
# sub_process = multiprocessing.Process(target=info_print, kwargs={"age": 1.1, "name": "laifu"})
# sub_process.start()
args+kwargs参数使用
# 元祖+字典方式传参
sub_process = multiprocessing.Process(target=info_print, args=("梁来福",), kwargs={"age": 1.1})
sub_process.start()
代码示例
import multiprocessing
def info_print(name, age):
print(name, age)
if __name__ == '__main__':
# 以元祖方式传参,元祖里面的元素顺序要和函数的参数顺序保持一致
# sub_process = multiprocessing.Process(target=info_print, args=("laifu", 1.1))
# sub_process.start()
# 以字典方式传参,字典里的key要和函数里面的参数名保持一致,没有顺序要求
# sub_process = multiprocessing.Process(target=info_print, kwargs={"age": 1.1, "name": "laifu"})
# sub_process.start()
# 元祖+字典方式传参
sub_process = multiprocessing.Process(target=info_print, args=("梁来福",), kwargs={"age": 1.1})
sub_process.start()
输出
梁来福 1.1
进程注意点
进程间不共享全局变量
代码示例
import multiprocessing
import time
# 定义全局变量列表
g_list = list()
# 添加数据任务
def add_data():
for i in range(5):
# 因为列表是可变类型,可以在原有内存的基础上修改数据,并且修改后内存地址不变,所以不需要加上global关键字
# 加"global"关键字,表示声明要修改全局变量的内存地址
g_list.append(i)
print("add:", i)
time.sleep(0.5)
print("添加数据完成:", g_list)
# 读取数据的任务
def read_data():
print("read:", g_list)
if __name__ == '__main__':
# 添加数据的子进程
add_process = multiprocessing.Process(target=add_data)
# 读取数据的子进程
read_process = multiprocessing.Process(target=read_data)
# 启动进程
add_process.start()
# 当前进程(主进程)等待添加数据的进程执行完成以后,再继续往下执行
add_process.join()
print("main:", g_list)
read_process.start()
输出
add: 0
add: 1
add: 2
add: 3
add: 4
添加数据完成: [0, 1, 2, 3, 4]
main: []
read: []
图例展示
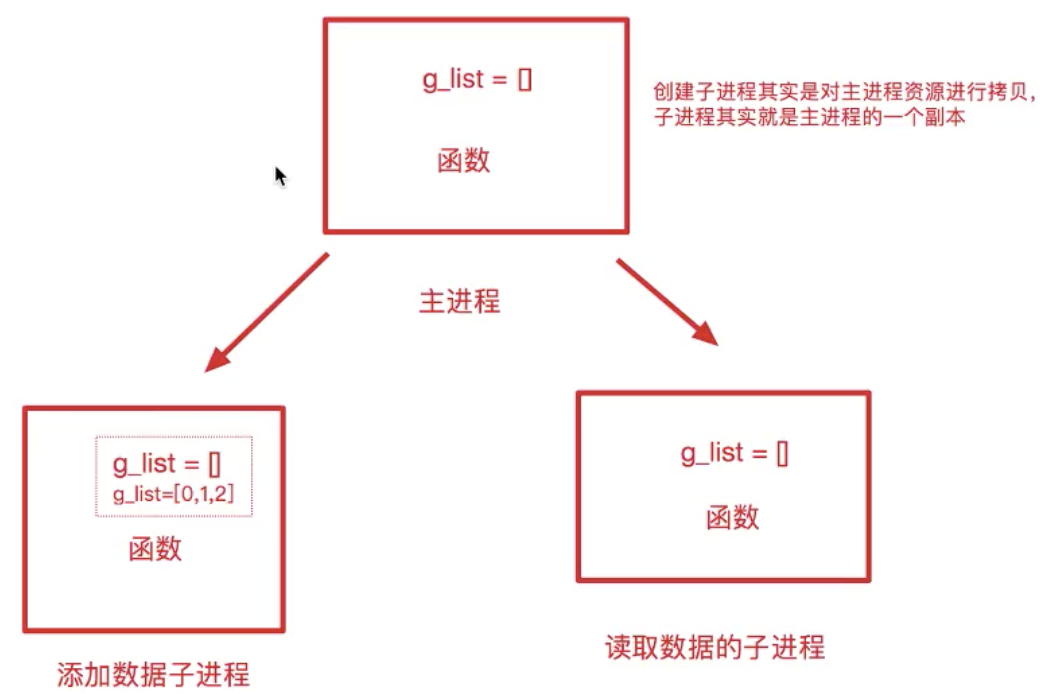
注意问题
问题描述
对于Linux和Mac主进程执行的代码不会进程拷贝,但是对于Windows系统来说主进程执行的代码也会进行拷贝;所以对于Windows来说创建子进程的代码如果进程拷贝执行相当于递归无限制进行创建子进程,会报错
解决
添加判断是否是主模块来解决
理解说明
直接执行的模块就是主模块,那么直接执行的模块里面就应该添加判断是否是主模块的代码
好处作用
1、防止别人导入文件的时候执行main里面的代码
2、防止Windows系统递归创建子进程的问题
主进程会等待所有的子进程执行完再退出
方法1:守护主线程
代码示例
import multiprocessing
import time
def task():
while True:
print("任务执行中...")
time.sleep(0.5)
if __name__ == '__main__':
sub_process = multiprocessing.Process(target=task)
# 把子进程设置成为守护主进程(主进程退出,子进程直接销毁)
sub_process.daemon = True
sub_process.start()
# 主进程延时2秒钟
time.sleep(2)
print("Over")
输出
任务执行中...
任务执行中...
任务执行中...
任务执行中...
Over
方法2:
退出主进程前,让子进程进行销毁
代码示例
import multiprocessing
import time
def task():
while True:
print("任务执行中...")
time.sleep(0.5)
if __name__ == '__main__':
sub_process = multiprocessing.Process(target=task)
# 把子进程设置成为守护主进程(主进程退出,子进程直接销毁)
# sub_process.daemon = True
sub_process.start()
# 主进程延时2秒钟
time.sleep(2)
# 退出主线程前,先让子进程进行销毁
sub_process.terminate()
print("Over")
输出
任务执行中...
任务执行中...
任务执行中...
任务执行中...
Over

